Section 5 Quelles questions intéressantes pour une “fouille de données” sur cette base ?
Quelles sont les questions intéressantes que l’on peut se poser ? Qu’est-ce qu’on va pouvoir mettre en évidence à partir de ces données ?
D’abord, on pourrait caractériser les logements fanciliens selon le type de logement (appartement, maison, HLM, …), la superficie, le nombre de pièces, le nombre de personnes y habitant, le statut d’occupation (propriétaire, locataire, …). Ensuite, on pourrait décrire plus précisément les pièces du logement en termes de confort (baignoire / douche, salle climatisée, moyen de chauffage), ainsi que les parties communes de l’immeuble (ascenseur, place de stationnement). Enfin, on pourrait étudier les caractéristiques des occupants de ces logements, et en premier lieu ici ce que l’Insee appelle la “personne de référence du ménage”. Par ailleurs, toutes ces analyses peuvent être réalisées en comparant les différentes communes de la région, ou à un niveau géographique plus fin par quartiers, arrondissements ou encore IRIS.
Pour manipuler cette base et répondre à quelques-unes de ces questions, nous allons nous concentrer sur la commune de Paris, et allons chercher à reproduire des statistiques publiées sur le site de l’Insee. Nous produirons principalement, lors de cette séance, des tableaux de statistiques, l’analyse graphique fera en effet l’objet d’une séance entière car elle nécessite la présentation détaillée de la “grammaire” Ggplot.
Avant cela, si les tables de données (“RP” et “meta”) ne sont plus dans votre environnement local, il faut de nouveau les importer à partir de l’enregistrement précédemment effectué dans le dossier ‘data’ de votre projet. Pour cela, il faut utiliser la fonction readRDS(), comme ci-dessous :
5.1 Caractéristiques des logements de la commune de Paris
Sur le site de l’Insee, vous pouvez trouver les statistiques générales sur les logements à Paris en 2019 ici.
Comme nous devons utiliser la pondération pour avoir des statistiques représentatives de la population française, une manière de faire est d’utiliser une méthode de comptage par variable catégorielle en indiquant la pondération à utiliser. La fonction count() avec l’argument wt= est un des moyens assez efficace d’y arriver. Cela nous donnera le nombre de ménages concernés par la caractéristique étudiée (par défaut, la variable créée s’appelle “n”, on peut la renommer dans une étape ultérieure avec la fonction rename()). Souvent, c’est aussi les pourcentages que l’on souhaite avoir, il faudra alors créer une variable faisant la proportion de chaque catégorie sur le nombre total de logements, en utilisant la fonction mutate() et la fonction prop.table(). Le package janitor permet enfin d’ajouter une ligne totale (ou une colonne totale selon ce qu’on souhaite faire) avec la fonction adorn_totals(), argument “row” pour avoir le total en ligne.
A partir de ces indications, afficher le tableau suivant à partir d’un code utilisant le langage tidyverse et en une seule procédure (sans nécessairement créer de table dans votre environnement) :
| Type de logement | Effectif | Pourcentage |
|---|---|---|
| Maison | 11 260 | 0.8 |
| Appartement | 1 346 430 | 96.9 |
| Autres | 31 685 | 2.3 |
| Total | 1 389 375 | 100.0 |
library(tidyverse)
library(janitor)
library(gt)
RP %>%
filter(COMMUNE == "75056") %>%
count(TYPL_moda, wt=IPONDL) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, 'Type de logement'=TYPL_moda) %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0)Non sans grande surprise, la commune de Paris est constituée en majorité d’appartements, presque 97%.
Cherchons maintenant la répartition des logements parisiens par type, est-ce plutôt des résidences principales ou secondaires ? combien y a-t-il de logements vacants ?
| Catégorie de logement | Effectif | Pourcentage |
|---|---|---|
| Résidences principales | 1 137 759 | 81.9 |
| Résidences secondaires | 85 675 | 6.2 |
| Logements vacants | 120 295 | 8.7 |
| Logements occasionnels | 45 645 | 3.3 |
| Total | 1 389 375 | 100.1 |
RP %>%
filter(COMMUNE == "75056") %>%
mutate(CATL_moda=case_when(CATL == "1" ~ "Résidences principales",
CATL == "2" ~ "Logements occasionnels",
CATL == "3" ~ "Résidences secondaires",
CATL == "4" ~ "Logements vacants",
TRUE ~ "Autres"),
CATL_moda=fct_relevel(CATL_moda, c("Résidences principales", "Résidences secondaires",
"Logements vacants", "Logements occasionnels"))) %>%
count(CATL_moda, wt=IPONDL) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, 'Catégorie de logement'=CATL_moda) %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0)La plupart des logements parisiens sont des résidences principales (81,9%), alors que 6,2% sont des résidences secondaires ; à noter que la part des logements vacants n’est pas négligeable, elle s’élève à 8,7%.
Maintenant, affichons la seule colonne 2019 de ce tableau tiré de l’Insee , en mettant la ligne “Ensemble des résidences principales” plutôt en fin de tableau (ces 2 usages sont possibles, question de préférence…) ; attention au champ sur lequel porte ces moyennes…

RP %>%
filter(COMMUNE == "75056" & CATL== "1" & TYPL_moda != "Autres") %>%
group_by(TYPL_moda) %>%
summarise('2019' = weighted.mean(as.numeric(as.character(NBPI)), IPONDL, na.rm=T)) %>%
bind_rows(summarise(TYPL_moda = "Ensemble des résidences principales",
RP[RP$COMMUNE == "75056" & RP$CATL == "1" & RP$TYPL_moda != "Autres",],
'2019' = weighted.mean(as.numeric(as.character(NBPI)), IPONDL, na.rm=T))) %>%
rename(' ' = TYPL_moda) %>%
gt() %>%
fmt_number(columns = 2, dec_mark = ",", decimals = 1)A Paris, sur les seules résidences principales, les maisons comportent plus de pièces que les appartements, presque 2 pièces de plus en moyenne. Etant donné que la majorité des logements est constituée par des appartements, la moyenne de l’ensemble des résidences principales est la même que celle des appartements.
Etudions maintenant les résidences principales et l’ancienneté d’emménagement selon le statut d’occupation. Attention, ici il faut procéder en plusieurs étapes : d’abord créer un tableau donnant la répartition en nombre et en pourcentage des ménages par statut d’occupation, puis créer un second tableau donnant la moyenne de l’ancienneté d’emménagement en années par statut d’occupation, puis fusionner ces deux tableaux.
| Statut d'occupation | Nombre | Pourcentage | Ancienneté moyenne d'emménagement en année(s) |
|---|---|---|---|
| Propriétaire | 379 745 | 33.4 | 18.2 |
| Locataire | 701 943 | 61.7 | 10.3 |
| Logé gratuitement | 56 071 | 4.9 | 10.4 |
| Total | 1 137 759 | 100.0 | 13.0 |
t1 <- RP %>%
filter(COMMUNE == "75056" & CATL=="1" & STOCD != "0") %>%
mutate(st_occupation=case_when(STOCD=="10" ~ "Propriétaire",
STOCD %in% c("21","22","23") ~ "Locataire",
STOCD=="30" ~ "Logé gratuitement"),
st_occupation=fct_relevel(st_occupation, c("Propriétaire",
"Locataire",
"Logé gratuitement"))) %>%
count(st_occupation, wt=IPONDL) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Nombre=n)
t2 <- RP %>%
filter(COMMUNE == "75056" & CATL=="1" & !STOCD %in% c("0", "ZZ")) %>%
mutate(st_occupation=case_when(STOCD=="10" ~ "Propriétaire",
STOCD %in% c("21","22","23") ~ "Locataire",
STOCD=="30" ~ "Logé gratuitement"),
st_occupation=fct_relevel(st_occupation, c("Propriétaire",
"Locataire",
"Logé gratuitement"))) %>%
group_by(st_occupation) %>%
summarise(anc_moy = weighted.mean(ANEM, IPONDL, na.rm=T)) %>%
bind_rows(summarise(st_occupation = "Total", RP[RP$COMMUNE == "75056" & RP$CATL=="1" & !RP$STOCD %in% c("0", "ZZ"),],
anc_moy = weighted.mean(ANEM, IPONDL, na.rm=T))) %>%
mutate(anc_moy=round(anc_moy, 1)) %>%
rename("Ancienneté moyenne d'emménagement en année(s)"=anc_moy)
t1 %>% left_join(t2, by=join_by(st_occupation)) %>%
rename("Statut d'occupation"=st_occupation) %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0)Il y a donc 1/3 de propriétaires à Paris quand on se concentre sur les résidences principales, et les propriétaires y sont présents depuis plus longtemps que les locataires : 18,2 ans en moyenne contre 10,3 ans.
Enfin, on peut vouloir comparer la moyenne des pièces des appartements parisiens par arrondissement par exemple.
| Arrondissement | Nombre moyen de pièces |
|---|---|
| 75101 | 2,6 |
| 75102 | 2,4 |
| 75103 | 2,4 |
| 75104 | 2,6 |
| 75105 | 2,6 |
| 75106 | 2,8 |
| 75107 | 3,0 |
| 75108 | 3,2 |
| 75109 | 2,7 |
| 75110 | 2,5 |
| 75111 | 2,3 |
| 75112 | 2,5 |
| 75113 | 2,6 |
| 75114 | 2,6 |
| 75115 | 2,6 |
| 75116 | 3,2 |
| 75117 | 2,7 |
| 75118 | 2,3 |
| 75119 | 2,6 |
| 75120 | 2,5 |
| Ensemble des appartements | 2,2 |
RP %>%
filter(COMMUNE == "75056" & CATL== "1" & TYPL_moda == "Appartement") %>%
group_by(ARM) %>%
summarise(Moy_pieces = weighted.mean(as.numeric(as.character(NBPI)), IPONDL, na.rm=T)) %>%
bind_rows(summarise(ARM = "Ensemble des appartements",
RP[RP$COMMUNE == "75056" & RP$CATL == "1" & RP$TYPL_moda != "Appartement",],
Moy_pieces = weighted.mean(as.numeric(as.character(NBPI)), IPONDL, na.rm=T))) %>%
rename(Arrondissement=ARM, 'Nombre moyen de pièces'=Moy_pieces) %>%
gt() %>%
fmt_number(columns = 2, dec_mark = ",", decimals = 1)Ainsi, si l’on veut créer des tableaux de répartition à une seule variable, on peut utiliser ces procédures qui se structurent toujours de la même façon. Au lieu de faire un copié-collé du code et de changer le nom des variables, autrement dit pour systématiser nos procédures, une astuce est de créer ses propres fonctions. C’est ce que nous allons étudier maintenant.
5.2 Systématiser nos procédures : construire une fonction
Pour ré-utiliser un code de façon plus automatique, créer des fonctions est très utile (et on peut même les stocker dans un fichier .r pour les réutiliser plus tard pour une autre étude).
L’idée est qu’à partir d’un bloc d’instructions ou de lignes de codes, on l’intègre dans une fonction qui portera un nom et qui pourra être appliquée sur les paramètres que l’on veut (table/objet différent, variables différentes) et qui nous retournera une valeur en sortie (qu’il faut préciser donc). Par exemple :
# Exemple fonction avec 3 arguments
nom_fonction <- function(data, var1, var2) {
expression... # Ce que la fonction fait
return() # Optionnel, mais la plupart du temps utilisé (!),
# pour sortir le résultat de la fonction
}
# L'appel de la fonction devra ainsi préciser la table de données sur laquelle
# l'appliquer et les autres arguments :
nom_fonction(data = nom_de_ma_table , var1 = nom_de_ma_variable1,
var2 = nom_de_ma_variable2)
# De plus, on pourra créer un nouvel objet (ici "tab_var") pour stocker la table
# qui est en valeur de sortie de la fonction :
tab_var <- nom_fonction(data = nom_de_ma_table , var1 = nom_de_ma_variable1,
var2 = nom_de_ma_variable2)Les arguments doivent donc être précisés en entrée de notre fonction, si on ne les précise pas cela nous retournera une erreur… à moins que l’on ait spécifié des valeurs par défaut (ce qui peut être utile si on utilise souvent les mêmes paramètres, par exemple la même base de données) ; il peut y avoir autant d’arguments que l’on souhaite.
Si l’on utilise le langage tidyverse, il faut connaître quelques petits “trucs” pour écrire une fonction. Le schéma suivant réalisé par Julien Barnier du CNRS nous sera très utile.
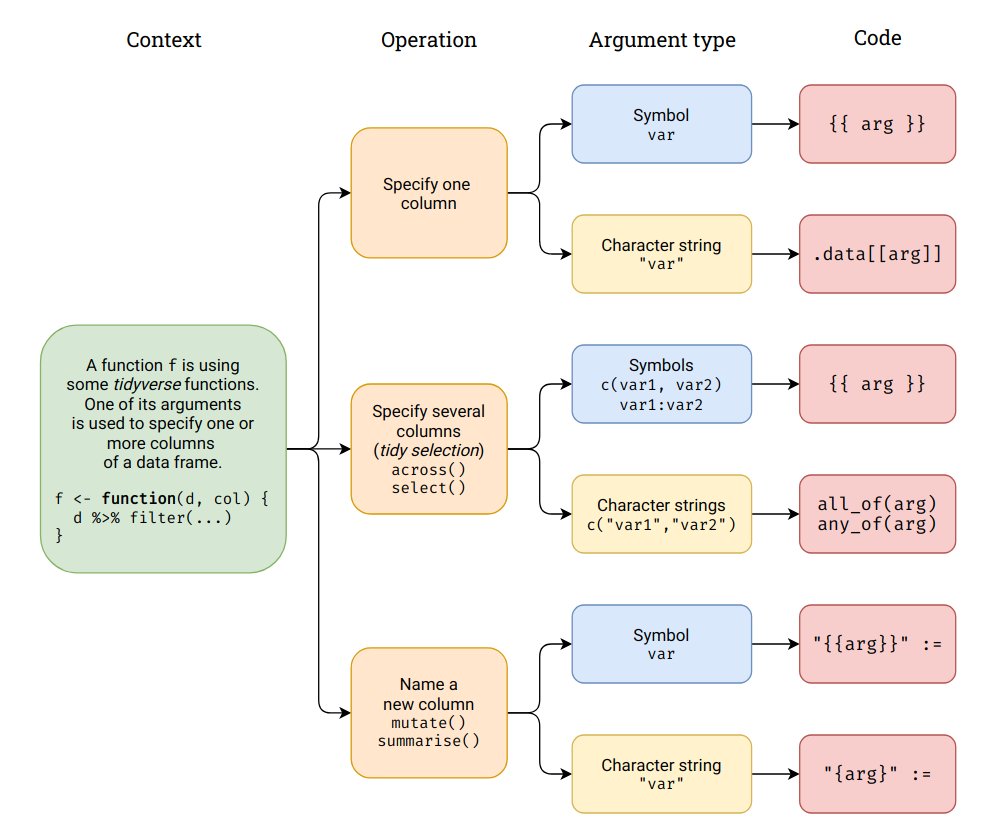
Pour une fonction utilisant le langage tidyverse
Source : Julien Barnier, https://twitter.com/lapply/status/1493908215796535296?s=20&t=p4aYIEV4GsGS3TGftPa0Nw.
Vous trouverez également des informations utiles ici ou là.
On peut d’abord créer une fonction reprenant le code précédent pour la construction de tableau. On l’appelle tableau, et on lui donne comme arguments “data”, “filtre_com”, “var_quali”, “pond” et “nom_var_quali”.
Dans le langage tidyverse, au sein d’une fonction, il faut appeler une variable avec des doubles-accolades {{ }}.
Si l’on utilise une fonction summarise(), une autre subtilité à connaître est que cette syntaxe summarise({{ nom_var }} = mean({{ var }}, na.rm=TRUE)) ne sera pas reconnue, car il faut indiquer non pas un “=” mais un “:=” pour que la fonction puisse être lue lorsque le nom donné à la variable est de type caractère ou “string”.
Enfin, il ne faut pas oublier de retourner un objet en sortie avec return().
Essayez donc de créer une fonction tableau(), reprenant le premier code de la section précédente et remise ci-dessous pour information :
RP %>%
filter(COMMUNE == "75056") %>%
count(TYPL_moda, wt=IPONDL) %>%
mutate(Pourcentage=prop.table(n)*100, Pourcentage=round(Pourcentage, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, 'Type de logement'=TYPL_moda) %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0)| Type de logement | Effectif | Pourcentage |
|---|---|---|
| Maison | 11 260 | 0.8 |
| Appartement | 1 346 430 | 96.9 |
| Autres | 31 685 | 2.3 |
| Total | 1 389 375 | 100.0 |
# library(tidyverse)
# library(janitor)
# library(gt)
tableau <- function(data, filtre_com, var_quali, pond=IPONDL, nom_var_quali){
tab <- data %>%
filter(COMMUNE == filtre_com) %>%
count({{ var_quali }}, wt={{ pond }}) %>%
mutate(Pourcentage=prop.table(n)*100, Pourcentage=round(Pourcentage, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, {{nom_var_quali}}:={{ var_quali }})
return(tab)
}On peut vérifier qu’on obtient bien la même chose :
tableau(data=RP, filtre_com="75056", var_quali=TYPL_moda, nom_var_quali="Type de logement") %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0)| Type de logement | Effectif | Pourcentage |
|---|---|---|
| Maison | 11 260 | 0.8 |
| Appartement | 1 346 430 | 96.9 |
| Autres | 31 685 | 2.3 |
| Total | 1 389 375 | 100.0 |
Essayez d’écrire une seconde fonction somme() permettant de systématiser le code suivant qui donne un tableau de contingence du nombre de propriétaires par IRIS (cela nous servira pour plus tard…), en ajoutant une fonction de filtre qui peut contenir plusieurs variables. Pour cela, on va utiliser l’argument “…” (lire “dot”) : cet argument est très pratique si l’on ne sait pas combien il y aura de variable(s) dans la fonction à laquelle elle s’applique, c’est-à-dire autant 0 variable, 1 variable ou plus d’une variable ; mais elle peut aussi être “dangereuse” si on ne se souvient plus qu’on l’a créée et/ou si on ne fait pas attention à bien remplir les autres arguments avec les noms correspondants.
On va également introduire la fonction group_by() pour avoir les tableaux de contingence par IRIS.
RP %>%
filter(COMMUNE == "75056" & STOCD == "10") %>%
group_by(IRIS) %>%
summarise(nb_proprietaires = sum(IPONDL)) %>%
mutate(nb_proprietaires=round(nb_proprietaires, 0))# A tibble: 917 x 2
IRIS nb_proprietaires
<fct> <dbl>
1 751010101 107
2 751010102 52
3 751010103 35
4 751010201 472
5 751010202 302
6 751010203 511
7 751010204 328
8 751010206 95
9 751010301 584
10 751010302 34
# i 907 more rowssomme <- function(data, ..., var_gpe, nom_var, var1){
som_1 <- data %>%
filter(...) %>%
group_by({{var_gpe}}) %>%
summarise({{nom_var}}:=sum({{var1}}, na.rm=T)) %>%
mutate({{nom_var}}:=round({{nom_var}}, 0))
return(som_1)
}Vérifions :
somme(data=RP, COMMUNE == "75056" & STOCD == "10",
var_gpe=IRIS, nom_var=nb_proprietaires, var1=IPONDL) # A tibble: 917 x 2
IRIS nb_proprietaires
<fct> <dbl>
1 751010101 107
2 751010102 52
3 751010103 35
4 751010201 472
5 751010202 302
6 751010203 511
7 751010204 328
8 751010206 95
9 751010301 584
10 751010302 34
# i 907 more rowsLa création de fonctions est donc très utile pour avoir un code plus efficace ; il faut toutefois réfléchir à son usage avant de la créer pour savoir à quel point il faut systématiser les procédures utilisées, certains éléments devant être laissés probablement en-dehors de la fonction, comme dans l’exemple précédent le fait d’arrondir les chiffres. Il faut par ailleurs toujours vérfier, sur un ou deux exemples, que la fonction fonctionne bien, c’est-à-dire donne les mêmes résultats que le code initial.
Pour pouvoir les réutiliser ultérieurement, on peut les réécrire dans un nouveau script qu’on enregistre dans un dossier de notre projet qu’on intitule “fonctions” ; il suffira ensuite d’appeler ce programme avec la fonction source() :
source("fonctions/fonctions.R")