# Exemple fonction avec 3 arguments
nom_fonction <- function(data, var1, var2) {
expression... # Ce que la fonction fait
return() # Optionnel, mais la plupart du temps utilisé (!),
# pour sortir le résultat de la fonction
}
# L'appel de la fonction devra ainsi préciser la table de données sur laquelle
# l'appliquer et les autres arguments :
nom_fonction(data = nom_de_ma_table , var1 = nom_de_ma_variable1,
var2 = nom_de_ma_variable2)
# De plus, on pourra créer un nouvel objet (ici "tab_var") pour stocker la table
# qui est en valeur de sortie de la fonction :
tab_var <- nom_fonction(data = nom_de_ma_table , var1 = nom_de_ma_variable1,
var2 = nom_de_ma_variable2)6 Systématiser nos procédures : construire une fonction
Pour ré-utiliser un code de façon plus automatique, créer des fonctions est très utile (et on peut même les stocker dans un fichier .r pour les réutiliser plus tard pour une autre étude).
6.1 Principes généraux d’une fonction
L’idée est qu’à partir d’un bloc d’instructions ou de lignes de codes, on l’intègre dans une fonction qui portera un nom et qui pourra être appliquée sur les paramètres que l’on veut (table/objet différent, variables différentes) et qui nous retournera une valeur en sortie (qu’il faut préciser donc). Par exemple :
Les arguments doivent donc être précisés en entrée de notre fonction, si on ne les précise pas cela nous retournera une erreur… à moins que l’on ait spécifié des valeurs par défaut (ce qui peut être utile si on utilise souvent les mêmes paramètres, par exemple la même base de données) ; il peut y avoir autant d’arguments que l’on souhaite.
Si l’on utilise le langage tidyverse, il faut connaître quelques petits “trucs” pour écrire une fonction. Le schéma suivant réalisé par Julien Barnier du CNRS nous sera très utile.
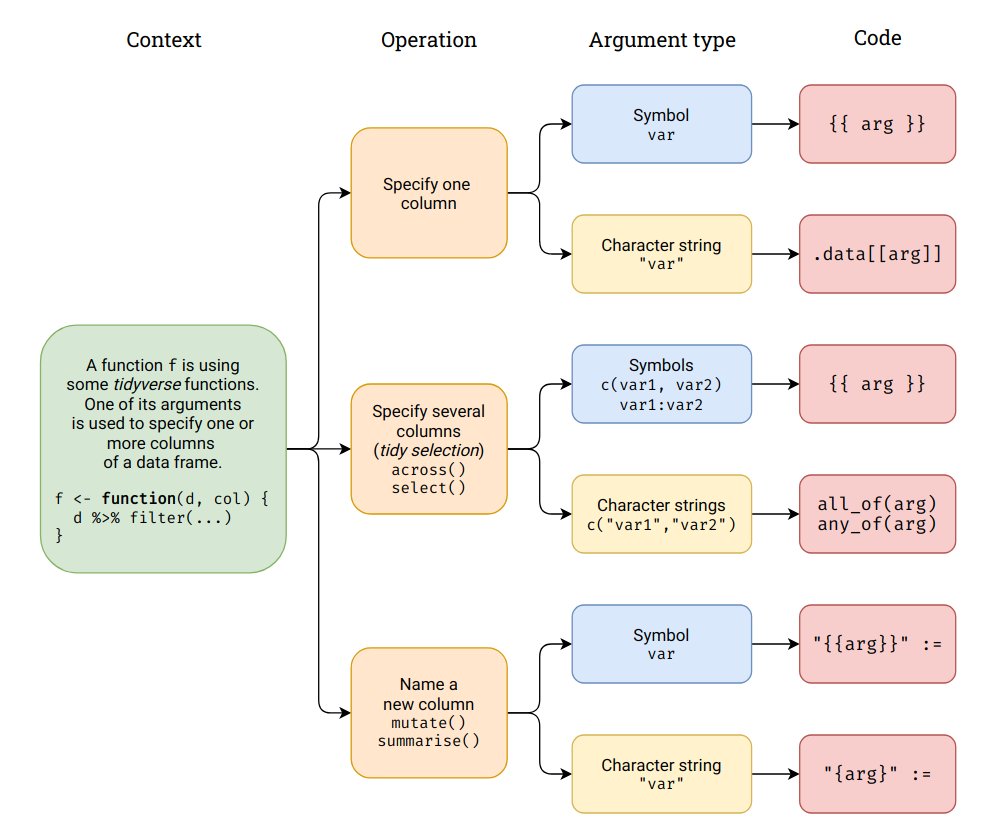 Source : Julien Barnier, https://twitter.com/lapply/status/1493908215796535296?s=20&t=p4aYIEV4GsGS3TGftPa0Nw.
Source : Julien Barnier, https://twitter.com/lapply/status/1493908215796535296?s=20&t=p4aYIEV4GsGS3TGftPa0Nw.
6.2 Exemples de fonctions
On peut d’abord créer une fonction reprenant le code de la section précédente pour la construction de tableau. On l’appelle tableau, et on lui donne comme arguments “data”, “filtre_dept”, “var_quali”, “pond” et “nom_var_quali”.
Dans le langage tidyverse, au sein d’une fonction, il faut appeler une variable avec des doubles-accolades { }.
Si l’on utilise une fonction summarise(), une autre subtilité à connaître est que cette syntaxe summarise({{ nom_var }} = mean({{ var }}, na.rm=TRUE)) ne sera pas reconnue, car il faut indiquer non pas un = mais un := pour que la fonction puisse être lue lorsque le nom donné à la variable est de type caractère ou “string”.
Enfin, il ne faut pas oublier de retourner un objet en sortie avec return().
Essayez donc de créer une fonction tableau(), reprenant le premier code de la section précédente et remise ci-dessous pour information :
RP_final %>%
filter(DEPT == "75") %>%
mutate(SEXE_moda=case_when(SEXE=="1" ~ "Hommes", SEXE=="2" ~ "Femmes")) %>% #ne pas mettre cette ligne dans la fonction
count(SEXE_moda, wt=IPONDI) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, 'Sexe'=SEXE_moda) %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0) %>%
tab_header(title = "Population par sexe en 2019") %>%
tab_source_note(source_note = "Source : Insee, RP 2019 ; Champ : Paris.")
TipSolution
tableau <- function(data, filtre_dept, var_quali, pond=IPONDI, nom_var_quali){
tab <- data %>%
filter(DEPT == filtre_dept) %>%
count({{ var_quali }}, wt={{ pond }}) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, {{nom_var_quali}}:={{ var_quali }})
return(tab)
}On peut vérifier qu’on obtient bien la même chose :
RP_final %>%
mutate(SEXE_moda=case_when(SEXE=="1" ~ "Hommes", SEXE=="2" ~ "Femmes")) %>%
tableau(filtre_dept="75", var_quali=SEXE_moda, nom_var_quali="Sexe") %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0) %>%
tab_header(title = "Population par sexe en 2019") %>%
tab_source_note(source_note = "Source : Insee, RP 2019 ; Champ : Paris.")| Population par sexe en 2019 | ||
| Sexe | Effectif | Pourcentage |
|---|---|---|
| Femmes | 1 146 436 | 52.9 |
| Hommes | 1 019 195 | 47.1 |
| Total | 2 165 631 | 100.0 |
| Source : Insee, RP 2019 ; Champ : Paris. | ||
On a gagné 5 lignes de codes !
Si on a plusieurs filtres à mettre, comme on a pu le voir avec le 2nd tableau, on peut utiliser l’argument “…” (lire “dot”) : cet argument est très pratique si l’on ne sait pas combien il y aura de variable(s) dans la fonction à laquelle elle s’applique, c’est-à-dire autant 0 variable, 1 variable ou plus d’une variable ; mais elle peut aussi être “dangereuse” si on ne se souvient plus qu’on l’a créée et/ou si on ne fait pas attention à bien remplir les autres arguments avec les noms correspondants. Si on réécrit la fonction tableau et qu’on l’applique au 2nd tableau créé précédemment, cela donnerait ceci :
tableau <- function(data, ..., var_quali, pond=IPONDI, nom_var_quali){
tab <- data %>%
filter(...) %>%
count({{ var_quali }}, wt={{ pond }}) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, {{nom_var_quali}}:={{ var_quali }})
return(tab)
}
RP_final %>%
mutate(TACT_moda=case_when(TACT == "11" ~ "Actifs ayant un emploi",
TACT == "12" ~ "Chômeurs",
TACT == "22" ~ "Élèves, étudiants et stagiaires non rémunérés",
TACT == "21" ~ "Retraités ou préretraités",
TRUE ~ "Autres inactifs"),
TACT_moda=fct_relevel(TACT_moda, c("Actifs ayant un emploi", "Chômeurs",
"Élèves, étudiants et stagiaires non rémunérés",
"Retraités ou préretraités", "Autres inactifs"))) %>%
tableau(DEPT == "75" & !AGEREVQ %in% c("0", "5", "10", "65", "70", "75", "80", "85", "90", "95",
"100", "105", "110", "115", "120"),
var_quali=TACT_moda, nom_var_quali="Type d'activité") %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0) %>%
tab_header(title = "Population de 15-64 ans par type d'activité en 2019") %>%
tab_source_note(source_note = "Source : Insee, RP 2019 ; Champ : Paris.")| Population de 15-64 ans par type d'activité en 2019 | ||
| Type d'activité | Effectif | Pourcentage |
|---|---|---|
| Actifs ayant un emploi | 1 042 588 | 69.3 |
| Chômeurs | 135 014 | 9.0 |
| Élèves, étudiants et stagiaires non rémunérés | 192 205 | 12.8 |
| Retraités ou préretraités | 38 512 | 2.6 |
| Autres inactifs | 95 944 | 6.4 |
| Total | 1 504 263 | 100.1 |
| Source : Insee, RP 2019 ; Champ : Paris. | ||
Une autre façon de faire serait de créer un vecteur qui contiendrait ces différents filtres mais qu’il faudrait combiner dans une chaîne de caractères, ce qui est possible avec la fonction paste0(), et l’insérer ensuite dans la ligne de code dplir en utilisant eval(parse(text=)) pour convertir cette chaîne de caractéres en une expression (parse(text=)) pour que R puisse l’évaluer/le calculer avec la fonction eval().
tableau_bis <- function(data, vars_filtre, var_quali, pond=IPONDI, nom_var_quali){
text_filtre <- paste0("(", vars_filtre, ")", collapse = " & ")
tab1 <- data %>%
filter(eval(parse(text = text_filtre))) %>%
count({{ var_quali }}, wt={{ pond }}) %>%
mutate(Pourcentage=round(prop.table(n)*100, 1)) %>%
adorn_totals("row") %>%
rename(Effectif=n, {{nom_var_quali}}:={{ var_quali }})
return(tab1)
}
# Attention, comme les filtres sont contenues dans des " ", il faut à l'intérieur des
# filtres utiliser les ' ' plutôt que les " "
mes_filtres <- c("DEPT == '75'", "!AGEREVQ %in% c('0', '5', '10', '65', '70', '75',
'80', '85', '90', '95', '100', '105',
'110', '115', '120')")
RP_final %>%
mutate(TACT_moda=case_when(TACT == "11" ~ "Actifs ayant un emploi",
TACT == "12" ~ "Chômeurs",
TACT == "22" ~ "Élèves, étudiants et stagiaires non rémunérés",
TACT == "21" ~ "Retraités ou préretraités",
TRUE ~ "Autres inactifs"),
TACT_moda=fct_relevel(TACT_moda1, c("Actifs ayant un emploi", "Chômeurs",
"Élèves, étudiants et stagiaires non rémunérés",
"Retraités ou préretraités", "Autres inactifs"))) %>%
tableau_bis(mes_filtres, var_quali=TACT_moda, nom_var_quali="Type d'activité") %>%
gt() %>%
fmt_number(columns = 2, sep_mark = " ", decimals = 0) %>%
tab_header(title = "Population de 15-64 ans par type d'activité en 2019") %>%
tab_source_note(source_note = "Source : Insee, RP 2019 ; Champ : Paris.")On peut également créer une fonction pour permettre de récupérer plus rapidement les libellés des variables à partir du fichier de métadonnées :
# Pour la fonction mutate, on est de nouveau obligé d'utiliser l'expression
# 'eval(parse(text={{ cod_var }}))' sinon R ne comprend pas que la variable
# utilisée est une expression de type caractère
libelles_var <- function(data, cod_var, new_var){
levels_var <- meta[meta$COD_VAR=={{ cod_var }}, ]$COD_MOD
labels_var <- meta[meta$COD_VAR=={{ cod_var }}, ]$LIB_MOD
data %>% mutate({{ new_var }} := factor(eval(parse(text={{ cod_var }})),
levels = levels_var, labels = labels_var))
}
# Autre possibilité, utiliser la fonction `sym()` (qui crée un symbole à partir
# d'une chaîne de caractères) avec les "!!" (opérateur bang-bang qui permet de
# forcer l'évaluation d'une partie d'une expression avant le reste) :
# libelles_var <- function(data, cod_var, new_var){
#
# levels_var <- meta[meta$COD_VAR=={{ cod_var }}, ]$COD_MOD
# labels_var <- meta[meta$COD_VAR=={{ cod_var }}, ]$LIB_MOD
# data %>% mutate({{ new_var }} := factor(!!sym({{ cod_var }}),
# levels = levels_var,
# labels = labels_var))
#
# }Enfin, essayez d’écrire une seconde fonction somme() permettant de systématiser le code utilisée en fin de 1ère séance et qui donnait un tableau de contingence du nombre de personnes caractériées par son statut par commune (cela nous servira pour plus tard…) ; le voici pour rappel :
RP_final %>%
group_by(COM) %>%
count(TACT, wt=IPONDI) %>%
mutate(n=round(n)) %>%
pivot_wider(names_from = TACT, values_from = n)
TipSolution
somme <- function(data, var_gpe, nom_var){
som <- data %>%
group_by({{var_gpe}}) %>%
count({{nom_var}}, wt=IPONDI) %>%
mutate(n=round(n)) %>%
pivot_wider(names_from = {{nom_var}}, values_from = n)
return(som)
}Vérifions :
somme(data=RP_final, COM, TACT)# A tibble: 137 × 8
# Groups: COM [137]
COM `11` `12` `21` `22` `23` `24` `25`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 75101 8366 941 2630 1423 1628 252 676
2 75102 13118 1378 2148 1617 2499 272 576
3 75103 19239 2085 4589 2947 3630 446 1100
4 75104 15227 1863 4508 2764 3268 480 1000
5 75105 27378 2611 10607 9138 6189 923 1369
6 75106 18073 1842 8180 6326 3742 1097 1012
7 75107 23394 2165 9573 5659 5312 1652 1112
8 75108 18254 1565 5297 3999 4693 1063 779
9 75109 34155 3482 7264 5201 7656 892 1377
10 75110 46454 6343 10645 7083 11481 1241 3273
# ℹ 127 more rowsLa création de fonctions est donc très utile pour avoir un code plus efficace ; il faut toutefois réfléchir à son usage avant de la créer pour savoir à quel point il faut systématiser les procédures utilisées, certains éléments devant être laissés probablement en-dehors de la fonction, comme dans l’exemple précédent le fait d’arrondir les chiffres. Il faut par ailleurs toujours vérfier, sur un ou deux exemples, que la fonction fonctionne bien, c’est-à-dire donne les mêmes résultats que le code initial.
Pour pouvoir les réutiliser ultérieurement, on peut les réécrire dans un nouveau script qu’on enregistre dans un dossier de notre projet qu’on intitule “fonctions” ; il suffira ensuite d’appeler ce programme avec la fonction source() :
source("fonctions/fonctions.R")